
Published on: August 29, 2023 Updated 2 times since publishing
SafetyDetectives spoke with Davit Buniatyan, the CEO and Co-Founder of Activeloop, a company revolutionizing the way deep learning teams manage multi-modal datasets. As AI and machine learning evolve, data management tools must keep pace, something Activeloop is keenly focused on. Buniatyan delves into how their AI-native format based on tensors is changing the game, especially in light of the current GPU shortage. He also shares his insights into the primary safety concerns when integrating private company data with Large Language Models.
Hi, Davit. Thank you for your time. Can you talk about your journey and your role at Activeloop?
I’m the Founder & CEO at Activeloop, the database for AI company that helps teams ship AI products fast without the need to build complex data infrastructure by themselves. My journey leading up to this role has been quite an adventure. I started by pursuing a Ph.D. at Princeton, studying neural networks in mice brains – which required much thought to manage this complex data efficiently. Fast forward a couple of years and Y Combinator residency. Activeloop helps teams manage their multi-modal data and connect it to AI seamlessly, with teams at large organizations, startups, or research institutions using Activeloop.
What are the flagship features of Activeloop?
At Activeloop, we bridge the gap between AI model training and production by facilitating data streaming, querying, versioning, and visualization of all AI data. Activeloop’s primary offering is Deep Lake, a multi-modal database designed for AI. We allow developers to connect their vector embeddings, documents, images, videos, etc., to Large Language Models or train their deep learning models. Thanks to the fact we store all the data in a robust AI-native format, companies can store all their data and metadata in one place and stream them to ML models in real time as the training happens, which means they can utilize computing resources efficiently. Deep Lake also helps you visualize all that data in-browser and seamlessly query or version control it.
How does Activeloop address deep learning teams’ challenges in managing multi-modal datasets? What differentiates modern data management tools from traditional ones, especially when handling diverse datasets?
The primary challenge of storing multimodal data is that most teams need help because they can’t do it with legacy solutions. Traditional data management tools were not designed to handle the unique challenges posed by diverse and large-scale datasets used in AI research. They tend to be slow and cumbersome when working with unstructured data such as images or videos with attached metadata. Activeloop, on the other hand, provides a streamlined approach to storing and processing these complex datasets, making it more efficient for deep learning applications.
Here’s a simple illustration of the difference in infrastructure setup before and after adopting Activeloop.
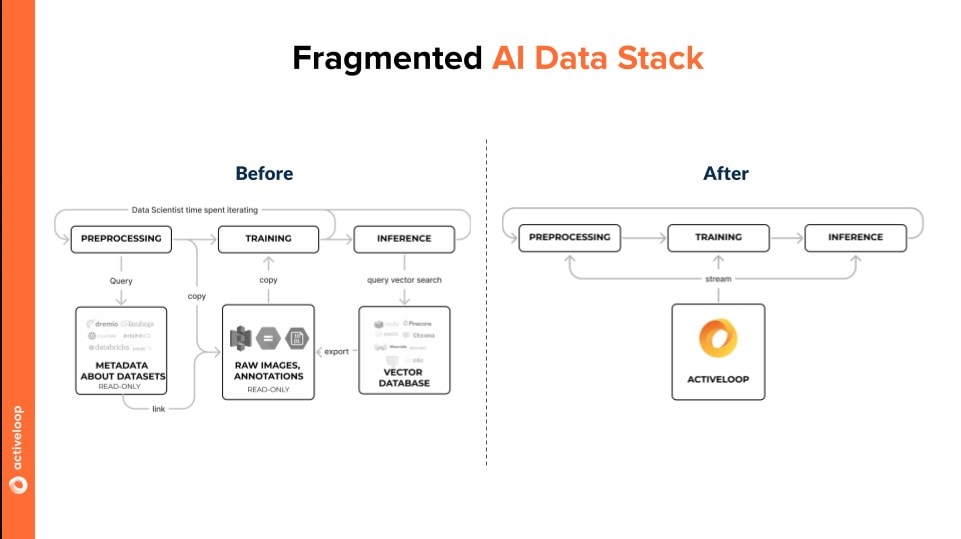
Because AI workflows typically require data and additional metadata (embeddings, masks, bounding boxes, etc.), legacy storage systems must be better suited for this. This results in companies needing to frankenstein together various solutions. With Activeloop, teams can store all this data, regardless of its type, together in one place and have a single view of it as it evolves with complete data lineage.
This is all thanks to our AI-native format based on tensors. What is a tensor? Imagine a warehouse of crates. A single crate holding a toy car is like a basic tensor called a scalar. A row of different toys is a vector, a tensor with a series of data. A grid of stacked crates is like a matrix. The whole 3D arrangement of crates in the warehouse represents a higher-dimensional tensor. In AI, tensors help organize data for the AI model to process.
Thanks to this format, we can store and manage multi-modal data for AI and stream it in real-time to ML models as the training is happening.
Given the current GPU shortage, how do you see the role of data streaming for machine learning
The GPU shortage certainly impacts AI operations, especially training large models. Data streaming for machine learning becomes pivotal in this context. Streaming allows for continuous, on-the-fly processing instead of batching and loading large amounts of data at once, which can bottleneck GPU resources. This minimizes idle GPU time and maximizes efficiency. Think of it like a just-in-time supply chain but for data. Adapting to hardware constraints, especially amid global compute shortage, while ensuring our models are trained effectively is crucial to succeed.
Considering the rapid evolution of AI and ML, what are some anticipated advancements in data management tools?
As AI and machine learning evolve, we anticipate significant advancements in data management tools. One area we are particularly excited about is the development of vector databases that can efficiently handle embeddings generated by foundation models. These embeddings capture complex patterns in data and require specialized storage and search capabilities. Activeloop is already a pioneer in this space, with our tensor data format also acting as a vector datastore by default. We are constantly working on enhancing our offerings to keep pace with advancements in the AI landscape.
What are the primary safety concerns connecting private company data to Large Language Models?
- Data Confidentiality: The cornerstone of any data integration is ensuring that the data remains confidential. We need to ensure that when sensitive data is exposed to models, there’s no risk of that data being leaked, accessed, or unintentionally revealed. As the recent case with Samsung showed, employees of even big companies don’t realize that they might be sending sensitive data to third parties. Being able to deploy LLMs privately requires open-source, serverless solutions that only add a little complexity to your existing infrastructure, like Deep Lake.
- Model Hallucination: This refers to a scenario where the model, in trying to generate responses, might inadvertently produce outputs that seem accurate but are, in fact, baseless or purely speculative. The insights derived from the model must be based on factual data and not just the model’s internal biases or speculations. This is where using a database for AI like Deep Lake by Activeloop is essential to provide accurate context to the Large Language Model.
- Code Injection: With the advent of more dynamic models, there’s an emerging concern where malicious actors attempt to inject code or malicious commands into the model’s responses. Developers may take LLM output ‘as is and copy-paste it into their terminal, opening up ample opportunity for an attack. We must guard against this to ensure both data integrity and system security.
You can learn how to connect enterprise data to LLMs safely in Activeloop’s GenAI360 Certification course, taken by over 15,000+ leaders in AI.